You know what though? Sometimes it's good to explore things that don't have an obvious business use case. Things that are weird. Things that are pretty. Things that are ridiculous. Things like dynamical systems and chaos. And, if you happen to find there are applicable tidbits along the way (*hint, skip to the problem outline section*), great, otherwise just enjoy the diversion.
motivation
So what is a dynamical system? Dryly, a dynamical system is a fixed rule to describe how a point moves through geometric space over time. Pretty much everything that is interesting can be modeled as a dynamical system. Population, traffic flows, fireflies, and neurons can all be describe this way.
In most cases, you'll have a system of ordinary differential equations like this:
\begin{eqnarray*}
\dot{x_{1}} & = & f_{1}(x_{1},\ldots,x_{n})\\
\vdots\\
\dot{x_{n}} & = & f_{n}(x_{1},\ldots,x_{n})
\end{eqnarray*}
In most cases, you'll have a system of ordinary differential equations like this:
For example, the Fitzhugh-Nagumo model (which models a biological neuron being zapped by an external current):
\begin{eqnarray*} \dot{v} & = & v-\frac{v^{3}}{3}-w+I_{{\rm ext}}\\ \dot{w} & = & 0.08(v+0.7-0.8w) \end{eqnarray*}
In this case \(v\) represents the potential difference between the inside of the neuron and the outside (membrane potential), and \(w\) corresponds to how the neuron recovers after it fires. There's also an external current \(I_{{\rm ext}}\) which can model other neurons zapping the one we're looking at but could just as easily be any other source of current like a car battery. The numerical constants in the system are experimentally derived from looking at how giant squid axons behave. Basically, these guys in the 60's were zapping giant squid brains for science. Understand a bit more why I think your business use case is boring?
One of the simple ways you can study a dynamical system is to see how it behaves for a wide variety of parameter values. In the Fitzhugh-Nagumo case the only real parameter is the external current \(I_{{\rm ext}}\). For example, for what values of \(I_{{\rm ext}}\) does the system behave normally? For what values does it fire like crazy? Can I zap it so much that it stops firing altogether?
In order to do that you'd just decide on some reasonable range of currents, say \((0,1)\), break that range into some number of points, and simulate the system while changing the value of \(I_{{\rm ext}}\) each time.
\begin{eqnarray*} \dot{v} & = & v-\frac{v^{3}}{3}-w+I_{{\rm ext}}\\ \dot{w} & = & 0.08(v+0.7-0.8w) \end{eqnarray*}
In this case \(v\) represents the potential difference between the inside of the neuron and the outside (membrane potential), and \(w\) corresponds to how the neuron recovers after it fires. There's also an external current \(I_{{\rm ext}}\) which can model other neurons zapping the one we're looking at but could just as easily be any other source of current like a car battery. The numerical constants in the system are experimentally derived from looking at how giant squid axons behave. Basically, these guys in the 60's were zapping giant squid brains for science. Understand a bit more why I think your business use case is boring?
One of the simple ways you can study a dynamical system is to see how it behaves for a wide variety of parameter values. In the Fitzhugh-Nagumo case the only real parameter is the external current \(I_{{\rm ext}}\). For example, for what values of \(I_{{\rm ext}}\) does the system behave normally? For what values does it fire like crazy? Can I zap it so much that it stops firing altogether?
In order to do that you'd just decide on some reasonable range of currents, say \((0,1)\), break that range into some number of points, and simulate the system while changing the value of \(I_{{\rm ext}}\) each time.
chaos
There's a a lot of great ways to summarize the behavior of a dynamical system if you can simulate its trajectories. Simulated trajectories are, after all, just data sets. The way I'm going to focus on is calculation of the largest lyapunov exponent. Basically, all the lyapunov exponent says is, if I take two identical systems and start them going at slightly different places, how similarly do they behave?
For example, If I hook a car battery to two identical squid neurons at the same time, but one has a little bit of extra charge on it, does their firing stay in sync forever or do they start to diverge in time? The lyapunov exponent would measure the rate at which they diverge. If the two neurons fire close in time but don't totally sync up then the lyapunov exponent would be zero. If they eventually start firing at the same time then the lyapunov exponent is negative (they're not diverging, they're coming together). Finally, if they continually diverge from one another then the lyapunov exponent is positive.
As it turns out, a positive lyapunov exponent usually means the system is chaotic. No matter how close two points start out, they will diverge exponentially. What this means in practice is that, while I might have a predictive model (as a dynamical system) of something really cool like a hurricane, I simply can't measure it precisely enough to make a good prediction of where it's going to go. A really small measurement error, between where the hurricane actually is and where I measure it to be, will diverge exponentially. So my model will predict the hurricane heading into Texas when it actually heads into Louisanna. Yep. Chaos indeed.
problem outline
So I'm going to compute the lyapunov exponent of a dynamical system for some range of parameter values. The system I'm going to use is the Henon Map:
\begin{eqnarray*}x_{n+1} & = & y_{n}+1-ax_{n}^{2}\\y_{n+1} & = & bx_{n}\end{eqnarray*}
I choose the Henon map for a few reasons despite the fact that it isn't modeling a physical system. One, it's super simple and doesn't involve time at all. Two, it's two dimensional so it's easy to plot it and take a look at it. Finally, it's only got two parameters meaning the range of parameter values will make up a plane (and not some n-dimensional hyperspace) so I can make a pretty picture.
What does Hadoop have to do with all this anyway? Well, I've got to break the parameter plane (ab-plane) into a set of coordinates and run one simulation per coordinate. Say I let \(a=[a_{min},a_{max}]\) and \(b=[b_{min},b_{max}]\) and I want to look \(N\) unique \(a\) values and \(M\) unique \(b\) values. That means I have to run \(N \times M\) individual simulations!
Clearly, the situation gets even worse if I have more parameters (a.k.a a realistic system). However, since each simulation is independent of all the other simulations, I can benefit dramatically from simple parallelization. And that, my friends, is what Hadoop does best. It makes parallelization trivially simple. It handles all those nasty details (which distract from the actual problem at hand) like what machine gets what tasks, what to do about failed tasks, reporting, logging, and the whole bit.
So here's the rough idea:
- Use Hadoop to split the n-dimensional (2D for this trivial example) space into several tiles that will be processed in parallel
- Each split of the space is just a set of parameter values. Use these parameter values to run a simulation.
- Calculate the lyapunov exponent resulting from each.
- Slice the results, visualize, and analyze further (perhaps at higher resolution on a smaller region of parameter space), to understand under what conditions the system is chaotic. In the simple Henon map case I'll make a 2D image to look at.
implementation
Hadoop has been around for a while now. So when I implement something with Hadoop you can be sure I'm not going to sit down and write a java map-reduce program. Instead, I'll use Pig and custom functions for pig to hijack the Hadoop input format functionality. Expanding the rough idea in the outline above:
- Pig will load a spatial specification file that defines the extent of the space to explore and with what granularity to explore it.
- A custom Pig LoadFunc will use the specification to create individual input splits for each tile of the space to explore. For less parallelism than one input split per tile it's possible to specify the number of total splits. In this case the tiles will be split mostly evenly among the input splits.
- The LoadFunc overrides Hadoop classes. Specifically: InputFormat (which does the work of expanding the space), InputSplit (which represents the set of one or more spatial tiles), and RecordReader (for deserializing the splits into useful tiles).
- A custom EvalFunc will take the tuple representing a tile from the LoadFunc and use its values as parameters in simulating the system and computing the lyapunov exponent. The lyapunov exponent is the result.
And here is the pig script:
define LyapunovForHenon sounder.pig.chaos.LyapunovForHenon(); points = load 'data/space_spec' using sounder.pig.points.RectangularSpaceLoader(); exponents = foreach points generate $0 as a, $1 as b, LyapunovForHenon($0, $1); store exponents into 'data/result';
You can take a look at the detailed implementations of each component on github. See: LyapunovForHenon, RectangularSpaceLoader
running
$: cat data/space_spec 0.6,1.6,800 -1.0,1.0,800
Remember the system?
\begin{eqnarray*}x_{n+1} & = & y_{n}+1-ax_{n}^{2}\\y_{n+1} & = & bx_{n}\end{eqnarray*} Well, the spatial specification says (if I let the first line represent \(a\) and the second be \(b\)) that I'm looking at an \(800 \times 800\) (or 640000 independent simulations) grid in the ab-plane where \(a=[0.6,1.6]\) and \(b=[-1.0,1.0]\)
Now, these bounds aren't arbitrary. The Henon attractor that most are familiar with (if you're familiar with chaos and strange attractors in the least bit) occurs when \(a=1.4\) and \(b=0.3\). I want to ensure I'm at least going over that case.
result
$: cat data/result/part-m* | head 0.6 -1.0 9.132244649409043E-5 0.6 -0.9974968710888611 -0.0012539625419929572 0.6 -0.9949937421777222 -0.0025074937591903013 0.6 -0.9924906132665833 -0.0037665150764570965 0.6 -0.9899874843554444 -0.005032402237514987 0.6 -0.9874843554443055 -0.006299127065420516 0.6 -0.9849812265331666 -0.007566751054452304 0.6 -0.9824780976220276 -0.008838119048229768 0.6 -0.9799749687108887 -0.010113503950504331 0.6 -0.9774718397997498 -0.011392710785045064 $: cat data/result/part-m* > data/henon-lyapunov-ab-plane.tsv
To visualize I used this simple python script to get:
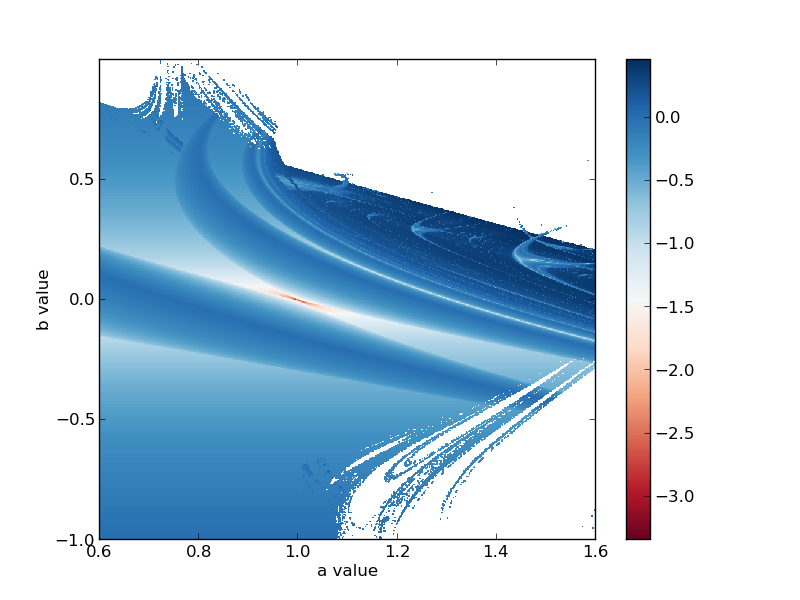
The big swaths of flat white are regions where the system becomes unbounded. It's interesting that the bottom right portion has some structure to it that's possibly fractal. The top right portion, between \(b=0.0\) and \(b=0.5\) and \(a=1.0\) to \(a=1.6\) is really the only region on this image that's chaotic (where the exponent is non-negative and greater than zero). There's a lot more structure here to look at but I'll leave that to you. As a followup it'd be cool to zoom in on the bottom right corner and run this again.
conclusion
So yes, it's possible to use Hadoop to do massively parallel scientific computing and avoid the question of big data entirely. Best of all it's easy.
The notion of exploding a space and doing something with each tile in parallel is actually pretty general and, as I've shown, super easy to do with Hadoop. I'll leave it to you to come up with your own way of applying it.
Very cool! Is it possible to use Hadoop and Pig's functionalities via Python?
ReplyDeleteThanks for this post.
Yes. See: http://pig.apache.org/docs/r0.11.1/cont.html
DeleteThank you so much for sharing this useful information about Hadoop, Here i gathered some new information keep updates...
ReplyDeleteHadoop training Chennai
I gathered a lot of information through this article.Every example is easy to undestandable and explaining the logic easily.Thanks!AWS course chennai | AWS Certification in chennai | AWS Certification chennai
ReplyDelete
ReplyDeleteIn sukere InfoTech we bolster a full chain advancement prepare from necessities definition, specification, engineering plan, coding, testing, approval, upkeep and support. Depending on your particular need our expert will take you through every period of arrangement giving you a sound direction on innovation and application choices.
web outlining in Chennai -Sukere infotechs
Thanks for sharing Valuable information. Greatful Info about hadoop. Really helpful. Keep sharing........... If it possible share some more tutorials.........
ReplyDeleteit’s really nice and meanful. it’s really cool blog. Linking is very useful thing.you have really helped lots of people who visit blog and provide them usefull information.
ReplyDeleteHadoop Training in Hyderabad
ReplyDeleteI have seen a lot of blogs and Info. on other Blogs and Web sites But in this Hadoop Blog Information is useful very thanks for sharing it........
Being new to the blogging world I feel like there is still so much to learn. Your tips helped to clarify a few things for me as well as giving..
ReplyDeleteBase SAS Training in Chennai
MSBI Training in Chennai
Before choosing a Job Oriented Training program it is important to evaluate your skills, interests, strength and weakness. Job Oriented Courses enable you to get a identity once you finish the same. Choose eNventsoft that suits you and make your career worthwhile.
ReplyDeleteGud information about Using Hadoop to Explore Chaos.keep updating
ReplyDeletemicrosoft dynamics crm course
now a days Hadoop has become the most effective course in the market In the year 2016 I had my PMP Certification in Chennai While I was under PMP Course I was able to know what will be the next updated Course that was Hadoop and by using hadoop to explore chaos is one element and good blog post Thankyou
ReplyDeleteGreat Article, thank you for sharing this useful information!!
ReplyDeleteLinux Online Training India
Online devops Training India
Online Hadoop admin Training India
Great Article, thank you for sharing this useful information!!
ReplyDeleteLinux Online Training India
Online devops Training India
Online Hadoop admin Training India
Thank you very much for your good information Hadoop Admin Online Training Bangalore
ReplyDeleteit is a good information
ReplyDeleteHadoop Admin Online Training Banglore
Thanks for sharing this blog. This very important and informative blog
ReplyDeleteLearned a lot of new things from your post! Good creation and HATS OFF to the creativity of your mind.
Very interesting and useful blog!
best Hadoop training in gurgaon
Australia Best Tutor is one of the best Online Assignment Help providers at an affordable price. Here All Learners or Students are getting best quality assignment help with reference and styles formatting.
ReplyDeleteVisit us for more Information
Australia Best Tutor
Sydney, NSW, Australia
Call @ +61-730-407-305
Live Chat @ https://www.australiabesttutor.com
Our Services
Online assignment help Australia
my assignment help Australia
assignment help
help with assignment
Online instant assignment help
Online Assignment help Services
It was really a nice article and i was really impressed by reading this Hadoop Administration Online Training Bnagalore
ReplyDeleteIt was really a nice article and i was really impressed by reading this Hadoop Admin Online Course Hyderabad
ReplyDeleteHello,
ReplyDeleteReally very good information sharing here, Appreciate your work, very informative blog on Hadoop. I just wanted to share information about The Best Hadoop Administration Certification | The Best MapReduce Certification.
If you are looking for Hadoop training in Hyderabad then definitely there are more good options available globally I have done googling for hadoop click on the link you can get the best institutes for your career.
ReplyDeleteThanks for sharing this valuable information to our vision Full Stack Training in Hyderabad
ReplyDeleteEach department of CAD have specific programmes which, while completed could provide you with a recognisable qualification that could assist you get a job in anything design enterprise which you would really like.
ReplyDeleteAutoCAD training in Noida
AutoCAD training institute in Noida
Best AutoCAD training institute in Noida
Thanks you for sharing this unique useful information content with us. Really awesome work. keep on blogging
ReplyDeleteHadoop Training in Chennai
Hadoop Training in Bangalore
Big data training in tambaram
Big data training in Sholinganallur
Big data training in annanagar
Big data training in Velachery
Big data training in Marathahalli
Good Post! Thank you so much for sharing this pretty post, it was so good to read and useful to improve my knowledge as updated one, keep blogging.
ReplyDeleteDevops Training in Chennai
Devops Training in Bangalore
This is a 2 good post. This post gives truly quality information.
ReplyDeleteRPA Training in Hyderabad
I was looking for this certain information for a long time. Thank you and good luck.
ReplyDeletepython training institute in chennai
python training in velachery
python training institute in chennai
This is very good content you share on this blog. it's very informative and provide me future related information.
ReplyDeleteData Science course in rajaji nagar | Data Science with Python course in chenni
Data Science course in electronic city | Data Science course in USA
Data science course in pune | Data science course in kalyan nagar
Learned a lot from your blog. Good creation and hats off to the creativity of your mind. Share more like this.
ReplyDeleteRobotics Process Automation Training in Chennai
RPA courses in Chennai
Robotic Process Automation Training
DevOps Training in Chennai
AWS Training in Chennai
Angularjs Training in Chennai
Very good brief and this post helped me alot. Say thank you I searching for your facts. Thanks for sharing with us!
ReplyDeleteangularjs online Training
angularjs Training in marathahalli
angularjs interview questions and answers
angularjs Training in bangalore
angularjs Training in bangalore
Thanks For Sharing This Very Useful And More Informative.
ReplyDeleteTekSlate Online Trainings
This is really an awesome post, thanks for it. Keep adding more information to this. Thank you!!
ReplyDeleteDevOps Online Training
All your points are excellent, keep doing great work.
ReplyDeleteSelenium Training in Chennai
software testing selenium training
ios developer course in chennai
Digital Marketing Course in Chennai
PHP Course in Velahery
PHP Course in Adyar
Wonderful article!!! It is very useful for improve my skills. This blog makes me to learn new thinks. Thanks for your content.
ReplyDeleteBest CCNA Training Institute in Bangalore
CCNA Certification in Bangalore
CCNA Training Bangalore
CCNA Training in Saidapet
CCNA Training in Chennai Kodambakkam
CCNA Training in Chennai
Informative blog! it was very useful for me.Thanks for sharing. Do share more ideas regularly.
ReplyDeleteSpoken English Classes in Bangalore
Spoken English Class in Bangalore
Spoken English Training in Bangalore
Spoken English Course near me
Spoken English Classes in Chennai
Spoken English Class in Chennai
Spoken English in Chennai
This information is impressive. I am inspired with your post writing style & how continuously you describe this topic. Eagerly waiting for your new blog keep doing more.
ReplyDeleteAndroid Training in Bangalore
Android Institute in Bangalore
Android Coaching in Bangalore
Android Coaching Center in Bangalore
Best Android Course in Bangalore
I really thank you for your innovative post.I have never read a creative ideas like your posts.here after i will follow your posts which is very much help for my career.
ReplyDeleteSalesforce Training in Guindy
Salesforce Training in Saidapet
Salesforce Training in Ambattur
Salesforce Training in Nolambur
Hi, Your blog is very impress to me. I am very glad to read your post. Thank you for your sharing.
ReplyDeletePHP Training Center in Bangalore
PHP Institutes in Bangalore
PHP Course in Adyar
PHP Course in Perambur
PHP Course in Nungambakkam
PHP Training in Saidapet
PHP Training in Navalur
PHP Course in Kelambakkam
Thank you for sharing such a great information with us.
ReplyDeleteLinux Course in Chennai
Linux Course
Linux Certification
Linux Training in Adyar
Linux Course in Velachery
Best Linux Training Institute in Tambaram
When I initially commented, I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get several emails with the same comment. Is there any way you can remove people from that service? Thanks.
ReplyDeleteAWS Interview Questions And Answers
AWS Training in Chennai | Best AWS Training in Chennai
AWS Training in Pune | Best Amazon Web Services Training in Pune
nice blog
ReplyDeletedata science training in bangalore
best data science courses in bangalore
data science institute in bangalore
data science certification bangalore
data analytics training in bangalore
data science training institute in bangalore
Very nice post here and thanks for it .
ReplyDeletebest training institute for hadoop in Marathahalli
best big data hadoop training in Marathahalli
hadoop training in Marathahalli
hadoop training institutes in Marathahalli
hadoop course in Marathahalli
ReplyDeleteGreat Post. Your article is one of a kind. Thanks for sharing.
Ethical Hacking Course in Chennai
Hacking Course in Chennai
Ethical Hacking Training in Chennai
Certified Ethical Hacking Course in Chennai
Ethical Hacking Course
Ethical Hacking Certification
Node JS Training in Chennai
Node JS Course in Chennai
Thank you for sharing wonderful information with us to get some idea about that content. check it once through
ReplyDeleteMachine Learning With TensorFlow Training and Course in Tel Aviv
| CPHQ Online Training in Beirut. Get Certified Online
Good information about Hadoop, but require more information Hadoop subset MapReduce
ReplyDeleteVery informative and impressive post you have written, this is quite interesting and i have went through it completely, an upgraded information is shared, keep sharing such valuable information.
ReplyDeleteBig data hadoop training in bangalore
Big data training in bangalore
Superb. I really enjoyed very much with this article here. Really it is an amazing article I had ever read. I hope it will help a lot for all. Thank you so much for this amazing posts and please keep update like this excellent article. thank you for sharing such a great blog with us.
ReplyDeletebest rpa training in bangalore
rpa training in pune | rpa course in bangalore
RPA training in bangalore
rpa training in chennai
Wonderful article, very useful and well explanation. Your post is extremely incredible. I will refer this to my candidates...
ReplyDeleteBest Devops Training in pune
Microsoft azure training in Bangalore
Power bi training in Chennai
A very nice guide. I will definitely follow these tips. Thank you for sharing such detailed article. I am learning a lot from you.
ReplyDeletepython Online training in chennai
python training institute in marathahalli
python training institute in btm
Python training course in Chennai
Very good to read thanks for the post
ReplyDeleteBest php training in chennai
I want to thank for sharing this blog, really great and informative. Share more stuff like this.
ReplyDeleteData Science Course in Chennai
Data Science Training in Chennai
Data Analytics Courses in Chennai
Big Data Analytics Courses in Chennai
Genuinely noteworthy article published by you. This might be advantageous for innumerable learners. One can speak and practice English in an effective way, just by downloading English Learning App on your own smartphone, which you can use whenever and wherever you want to practice your communication skills with experts.
ReplyDeletePractice English app | English Speaking App
ReplyDeleteIts really nice and informative.. Thanks for sharing
Php Training Institute in noida sector 16,
PlSql Training Institute in Noida sector 16,
Python Training Institute in Noida sector 16,
RPA Training Institute in Noida sector 16,
Salesforce Training Institute in Noida sector 16,
Sap fico Training Institute in Noida sector 16,
ERP Sap mm Training Institute in Noida Sector 16,
Sap Training Institute in Noida Sector 16,
SAS Training Institute in Noida Sector 16,
Blue Prism Training Institute in Noida,
Very Clear Explanation. Thank you to share this
ReplyDeleteRegards,
Devops Training Institute in Chennai
Wow wonderful post keep on posting
ReplyDeletesalesforce training in chennai
WOW! Really Nice Post! I personally believe that to maintain the standard of a blog all the hacks mentioned above are important. All points discussed were worth reading
ReplyDeleteand I’ll surely work with them all one by one.
CEH Training In Hyderbad
You are doing a great job. I would like to appreciate your work for good accuracy
ReplyDeleteCCNA Training Institute Training in Chennai
You are doing a great job. I would like to appreciate your work for good accuracy.
ReplyDeleteSocial Media Marketing Chennai
Amazing post thanks for sharing
ReplyDeletepython training in chennai
Thanks for sharing this informative blog..Keep posting
ReplyDeleteWebsite Designing Company in Bangalore | Website Designing Companies in Bangalore | Web Designers in Bangalore
Interview answers is a great resource for your readers here. Salesforceadmin interview questions as well. Hadoop interview questions too.
ReplyDeletenice blog, I like your good post, thanks for sharing great information.
ReplyDeleteLinux Training in Noida
Linux Training institute in Noida
Its a wonderful post and very helpful, thanks for all this information.
ReplyDeleteHadoop Training in Gurgaon
Excellent blog I visit this blog it's really awesome. The important thing is that in this blog content written clearly and understandable. The content of information is very informative.
ReplyDeleteOracle Fusion Financials Online Training
Oracle Fusion HCM Online Training
Oracle Fusion SCM Online Training
oracle Fusion Technical online training
Thanks for sharing such a good article having valuable information.best to learn Big Data and Hadoop Training course.
ReplyDeleteBig Data and Hadoop Training In Hyderabad
An amazing web journal I visit this blog, it's unbelievably wonderful. Oddly, in this blog's content made without a doubt and reasonable. The substance of data is informative.
ReplyDeleteOracle Fusion Financials Online Training
Oracle Fusion HCM Online Training
Oracle Fusion SCM Online Training
oracle Fusion Technical online training
Thanks for this information, I think it will come in handy in the future.
ReplyDeleteresearch topic in economics.
Your very own commitment to getting the message throughout came to be rather powerful and have consistently enabled employees just like me to arrive at their desired goals.
ReplyDeleteAnd indeed, I’m just always astounded concerning the remarkable things served by you. Some four facts on this page are undeniably the most effective I’ve had.
MATLAB TRAINING IN CHENNAI | Best MATLAB TRAINING Institute IN CHENNAI
EMBEDDED SYSTEMS TRAINING IN CHENNAI |Best EMBEDDED TRAINING Institute IN CHENNAI
MCSA / MCSE TRAINING IN CHENNAI |Best MCSE TRAINING Institute IN CHENNAI
CCNA TRAINING IN CHENNAI | Best CCNA TRAINING Institute IN CHENNAI
ANDROID TRAINING IN CHENNAI |Best ANDROID TRAINING Institute IN CHENNAI
This comment has been removed by the author.
ReplyDeleteiphongthuynet
ReplyDeleteiphongthuynet
iphongthuynet
iphongthuynet
iphongthuynet
iphongthuynet
iphongthuynet
iphongthuynet
iphongthuynet
Thank you for this post. This is very interesting information for me. Who can do my homework for me?
ReplyDeleteJika anda merasa sudah lumayan ahli, sebaiknya anda mencoba dengan pindah-pindah meja. Karena ini bisa membuat anda lebih mendapatkan banyak keuntungan.
ReplyDeleteasikqq
dewaqq
sumoqq
interqq
pionpoker
bandar ceme terbaik
hobiqq
paito warna
forum prediksi
bandar ceme online
ReplyDeleteGood explanation information
ReplyDeleteSanjary Kids is one of the best play school and preschool in Hyderabad,India. Give your child the best preschool experience by choosing the best playschool of Hyderabad in Abids. we provide programs like Play group,Nursery,Junior KG,Senior KG,and provides Teacher Training Program.
Preschool teacher training course in hyderabad
This comment has been removed by the author.
ReplyDeleteAwesome post. You Post is very informative. Thanks for Sharing.
ReplyDeleteHadoop Training in Noida
Such a nice blog, I really like what you write in this blog, I also have some relevant information about if you want more information.
ReplyDeleteWorkday HCM Online Training
Thanks for sharing your valuable information and time.
ReplyDeleteCCNA Training in Delhi
opencart quickbooks integration
ReplyDeleteThank you for sharing such a nice and really very helpful article
ReplyDeleteOracle Fusion Financials Online Training
Oracle Fusion SCM Online Training
Wow wonderful post keep on posting.
ReplyDeleteMachine Learning Training institute in Delhi
Machine Learning Training in Delhi
Great Article
ReplyDeleteIEEE Projects on Cloud Computing
Final Year Projects for CSE
JavaScript Training in Chennai
JavaScript Training in Chennai
Nice information, want to know about Selenium Training In Chennai
ReplyDeleteSelenium Training In Chennai
Selenium Training
Data Science Training In Chennai
Protractor Training in Chennai
jmeter training in chennai
Rpa Training Chennai
Rpa Course Chennai
Selenium Training institute In Chennai
Python Training In Chennai
I must appreciate you for providing such a valuable content for us. This is one amazing piece of article.Helped a lot in increasing my knowledge.sap basis training in bangalore
ReplyDeleteExcellent post, it will be definitely helpful for many people. Keep posting more like this.sap gts training in bangalore
ReplyDeleteinking is very useful thing.you have really helped lots of people who visit blog and provide them use full information.sap fiori training in bangalore
ReplyDeleteeally very nice blog information for this one and more technical skills are improve,i like that kind of post.SAP ABAP Training in Bangalore
ReplyDelete
ReplyDeleteReally very nice blog information for this one and more technical skills are improve,i like that kind of post.SAP ABAP Training in Bangalore
It’s great blog to come across a every once in a while that isn’t the same out of date rehashed material. Fantastic read.SAP ABAP Training in Bangalore
ReplyDeleteNice article thanks for sharing the post....!
ReplyDeleteqtp training
manual testing training
qlik sense training
oracle sql plsql training
Thank you for sharing such a nice and really very helpful article...
ReplyDeleteDevOps Training in Marathahalli - Bangalore | DevOps Training Institutes | DevOps Course Fees and Content | DevOps Interview Questions - eCare Technologies located in Marathahalli - Bangalore, is one of the best DevOps Training institute with 100% Placement support. DevOps Training in Bangalore provided by
DevOps Certified Experts and real-time Working Professionals with handful years of experience in real time DevOps Projects.
Thanks for Sharing This Article.It is very so much valuable content. I hope these Commenting lists will help to my website
ReplyDeleteworkday studio online training
top workday studio online training
best workday studio online training
ReplyDeleteThanks for Sharing This Article.It is very so much valuable content. I hope these Commenting lists will help to my website
workday studio online training
Thanks for Posting such an useful and informative stuff....
ReplyDeleteSalesforce admin Training
Setiap situs web yang memerlukan pemrosesan pembayaran online harus mengandalkan dan mengandalkan teknologi canggih untuk melindungi informasi keuangan rahasia pelanggan dan jika pelanggan merasa bahwa rincian 98toto
ReplyDeleteThak you for sharing your knowledge.And this is a great article.
ReplyDeleteKeep sharing your blog with others.
big data hadoop online training
This post is too good.very nice post.
ReplyDeleteThank you.
hadoop admin online training
very nice post.This blog is very useful for me.Really great blog.
ReplyDeleteThank you.
hadoop admin online course
hadoop admin online training
hadoop administration training
hadoop administration online training
Excellent information with unique content and it is very useful ...
ReplyDeleteIELTS Coaching in chennai
German Classes in Chennai
GRE Coaching Classes in Chennai
TOEFL Coaching in Chennai
spoken english classes in chennai | Communication training
Thanks For sharing a nice post ..
ReplyDeleteAndroid Training in Bangalore
Android Training
Android Online Training
Android Training in Hyderabad
Android Training in Chennai
Android Training in Coimbatore
Thanks for providing such a great information in the blog and also very helpful to all.learn best Oracle Fusion HCM Online Training.
ReplyDelete| Certification | Cyber Security Online Training Course|
Ethical Hacking Training Course in Chennai | Certification | Ethical Hacking Online Training Course|
CCNA Training Course in Chennai | Certification | CCNA Online Training Course|
RPA Robotic Process Automation Training Course in Chennai | Certification | RPA Training Course Chennai|
SEO Training in Chennai | Certification | SEO Online Training Course
Being new to the blogging world I feel like there is still so much to learn. Your tips helped to clarify a few things for me as well as giving..
ReplyDeletehadoop training in bangalore
oracle training in bangalore
hadoop training in acte.in/oracle-certification-training">oracle training
oracle online training
oracle training in hyderabad
hadoop training in chennai
We are well established IT and outsourcing firm working in the market since 2013. We are providing training to the people ,
ReplyDeletelike- Web Design , Graphics Design , SEO, CPA Marketing & YouTube Marketing.Call us Now whatsapp: +(88) 01537587949
: Digital Marketing Training
Free bangla sex video:careful
good post outsourcing institute in bangladesh
Thanks for sharing this great article. It made me understand few things about this concept which I never knew before. Keep posting such great articles so that I gain from it.
ReplyDeleteDevOps Training in Chennai
DevOps Course in Chennai
Congratulations! This is the great things. Thanks to giving the time to share such a nice information.Villas in Rajahmundry
ReplyDeleteApartments in Rajahmundry
Great Article. Thanks for sharing.
ReplyDeleteBest Bike Taxi Service in Hyderabad
Best Software Service in Hyderabad
Thank you so much for sharing a great content and very beneficial stuff that you have shared with the world. Primavera course in Chennai | Primavera p6 training online
ReplyDeletereally useful
ReplyDeletedevops Training in chennai | devops Course in Chennai
I am really happy to say it’s an interesting post to read . I learn new information from your article , you are doing a great job . Keep it up
ReplyDeletethanks for your informative article
ReplyDeletethank you
best-angular-training in chennai |
The angular platform provides flexibility to build mobile and web applications. It is a typescript based web application. Angular allows flexibility to develop applications and reuse code. It also gives maximum flexibility to increase speed and performance via web workers & server rendering. Mind Q Systems offers a complete Angular Training course for students with real-time experience.
ReplyDeleteThanks for sharing
ReplyDeleteWe will assist you in creating profiles & maintaining them in a professional manner. For more reach, we will assist you in creating paid campaigns and generating reach or leads from campaigns on daily basis
Very Informative blog thank you for sharing. Keep sharing.
ReplyDeleteBest software training institute in Chennai. Make your career development the best by learning software courses.
rpa training in chennai
Docker Training institute in Chennai
devops training in chennai
It has been simply incredibly generous with you to provide openly
ReplyDeletewhat exactly many individuals would’ve marketed for an eBook to end
up making some cash for their end, primarily given that you could
have tried it in the event you wanted.
mysql training in chennai
unix training in chennai
Software training institute in chennai
Amazing or I can say this is a remarkable article.
ReplyDeleteUOK BCom Result 2022
UOK BCom 1st Year Result 2022
UOK BCom 2nd Year Result 2022
UOK BCom 3rd Year Result 2022
mmorpg oyunlar
ReplyDeleteInstagram Takipçi Satın Al
Tiktok Jeton Hilesi
tiktok jeton hilesi
antalya saç ekimi
Instagram takipci
instagram takipçi satın al
metin2 pvp serverlar
instagram takipçi satın al
perde modelleri
ReplyDeleteMobil onay
Vodafone mobil ödeme bozdurma
nft nasıl alınır
ankara evden eve nakliyat
trafik sigortası
dedektör
WEBSİTE.KURMA
Ask Kitaplari
smm panel
ReplyDeleteSMM PANEL
iş ilanları
İnstagram takipçi satın al
hirdavatciburada.com
beyazesyateknikservisi.com.tr
SERVİS
tiktok jeton hile
I really enjoyed reading your article. I found this as an informative and interesting post, so i at Gati Packers And Movers Hyderabad with Gati Packers And Movers in Bangalore think it is very useful and knowledgeable. I at Gati Packers And Movers Pune would like to thank you for the effort you have made in writing this article. Have a great day!
ReplyDeleteThis comment has been removed by the author.
ReplyDelete
ReplyDeleteVery informative Blog by you for the people who are new to this industry. Your detailed blog solves all the queries with good explanation. Keep up the good work. Thanks for sharing! We have a website too. Feel free to visit anytime.
western dress for kids
western dress for girls kids
Very informative Blog by you for the people who are new to this industry. Your detailed blog solves all the queries with good explanation. Keep up the good work. Thanks for sharing! We have a website too. Feel free to visit anytime.
ReplyDeletekids western dress
western dress for girls
Very informative Blog by you for the people who are new to this industry. Your detailed blog solves all the queries with good explanation. Keep up the good work. Thanks for sharing! We have a website too. Feel free to visit anytime.
ReplyDeletepackers and movers in Mulund
packers and movers in Nerul
I am exteremly impressed by your blog, because its very powerful for the new readers and have lot of information with proper explanation. Keep up the good work. Thanks for sharing this wonderful blog! We also have a website. Please check out whenever and wherever you see this comment.
ReplyDeleteanniversary invitation card
birthday invitation card
I am exteremly impressed by your blog, because its very powerful for the new readers and have lot of information with proper explanation. Keep up the good work. Thanks for sharing this wonderful blog! We also have a website. Please check out whenever and wherever you see this comment.
ReplyDeletehouse warming invitation
invitation card
Your blog has a lot of material with clear explanations and is really effective for new readers, therefore I'm very impressed. Keep up the excellent work. Thank you for distributing this fantastic blog! Moreover, we have a website. When and whenever you see this comment, please check it out.
ReplyDeletedigital marketing company in mohali
SEO Company in Mohali
Thank you for sharing this amazing article.learn r for data science
ReplyDelete
ReplyDeleteYour blog has a lot of material with clear explanations and is really effective for new readers, therefore I'm very impressed. Keep up the excellent work. Thank you for distributing this fantastic blog! Moreover, we have a website. When and whenever you see this comment, please check it out.
Webp File Converter
Quick Convert
Your blog has a lot of material with clear explanations and is really effective for new readers, therefore I'm very impressed. Keep up the excellent work. Thank you for distributing this fantastic blog! Moreover, we have a website. When and whenever you see this comment, please check it out.
ReplyDeleteJPG File Converter
Quick Convert
Thanks for sharing this: comptia a+ online course
ReplyDeleteA market research consultant is a professional who helps businesses gather, analyze, and interpret information about their target markets. They play a crucial role in helping businesses make informed decisions about their products, services, and marketing strategies.
ReplyDeletethanks for valuable info
ReplyDeletegcp data engineer training in hyderabad